NORMAL ASICs
Reduce AI energy consumption by 1000x with thermodynamic computing.




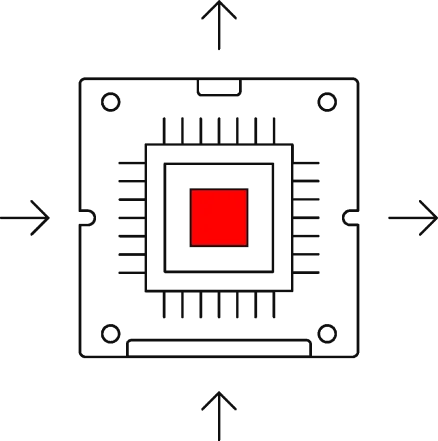


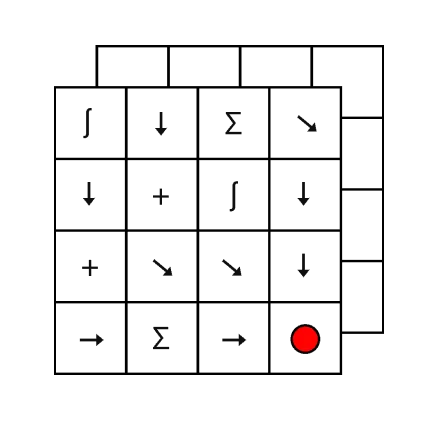



Instead of fighting noise, Normal ASICs embrace it. Our thermodynamic circuits evolve in continuous time, naturally solving equations associated with sampling, inference, and optimization.
Unlike traditional ASICs, Normal ASICs aren’t forced into deterministic regimes. Our chips operate asynchronously and statefully, enabling dense, low-latency information processing with minimal power overhead.
We co-design algorithms and hardware together, selecting physical substrates that directly realize the mathematical primitives needed for target workloads. This full-stack alignment unlocks new efficiency frontiers.