
Building an Open-Source Verilog Simulator with AI: 580K Lines in 43 Days
How one Normal engineer used AI agents to build a practical verification stack on top of CIRCT: simulation, formal verification, mutation testing, and more.

Commercial EDA toolchains cost teams millions of dollars a year across simulation, formal, synthesis, and physical design. The individual tools are well-understood, the specifications are public (IEEE 1800-2017), and open-source compiler infrastructure like CIRCT already exists.
We wanted to understand how far agentic AI could go on a well-specified but labor-intensive engineering problem.
Over 43 days in January and February 2026, we used AI Agents to land 2,968 commits on a CIRCT fork — adding a full event-driven simulator, VPI/cocotb integration, UVM runtime support, bounded model checking, logic equivalence checking, and mutation testing. The result is a practical, open-source verification stack that can simulate real-world protocol testbenches end-to-end.
This post is a technical account of what happened, what the numbers look like, and what we think it means.
What is CIRCT, and What Was Missing?
CIRCT (Circuit IR Compilers and Tools) is an LLVM-based infrastructure for hardware design and verification. It provides a rich set of intermediate representations: (HW, Comb, Seq, LLHD, Moore) and tools for parsing Verilog (circt-verilog, powered by slang), optimizing IR (circt-opt), and basic formal checking (circt-bmc, circt-lec).
What it did not have was a practical simulation runtime. You could parse Verilog into LLVM’s Intermediate Representation (MLIR) and lower it through various dialects, but you couldn’t actually run a testbench. The gap between “we can compile Verilog” and “we can simulate a design” was enormous.
Bridging that gap is exactly the kind of task where agentic AI shines: the specification is known (IEEE 1800), the interfaces are well-defined, and the work is largely volume — thousands of op handlers, system calls, edge cases — rather than fundamental research.
By the Numbers
The fork adds 580,430 lines across 3,846 files, with only 10,985 lines removed from upstream. The chart below shows the full story: cumulative lines of code (blue), test file count (purple), and weekly commit velocity (orange numbers along the bottom), with color-coded development phases and milestone annotations.
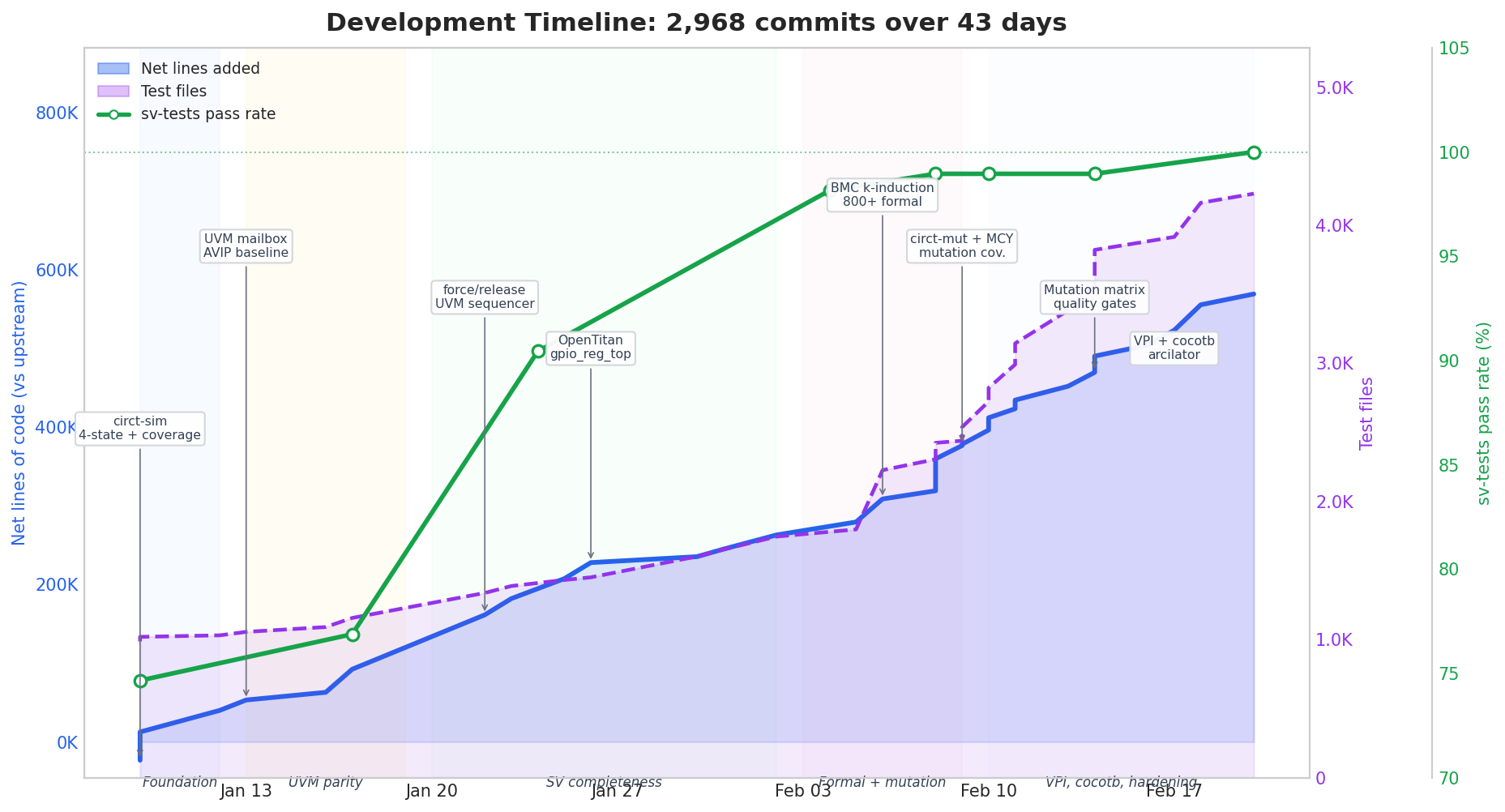
The pace started at ~25 commits/day in week 1 and peaked at 124 commits/day in week 7 (Feb 10–16). This isn’t because the AI got faster — it’s because the later work was more mechanical (regression infrastructure, test harnesses, quality gates) while the earlier work required more design iteration. Test files grew from 987 (upstream baseline) to 4,229 — a 4.3x increase, with a sharp inflection around Feb 6 when formal and mutation suites came online.
One of the main external drivers of progress was sv-tests, a test suite designed to check compliance with the SystemVerilog standard by the CHIPS Alliance. As of writing, the CIRCT project is at 73%, while the two main free simulators, Verilator and Icarus, are at 94% and 80%, respectively. The chart above shows our progress of taking CIRCT to 100% IEEE support in a month and a half.
Where the Work Went
Every one of the 2,968 commits is accounted for in a named category:
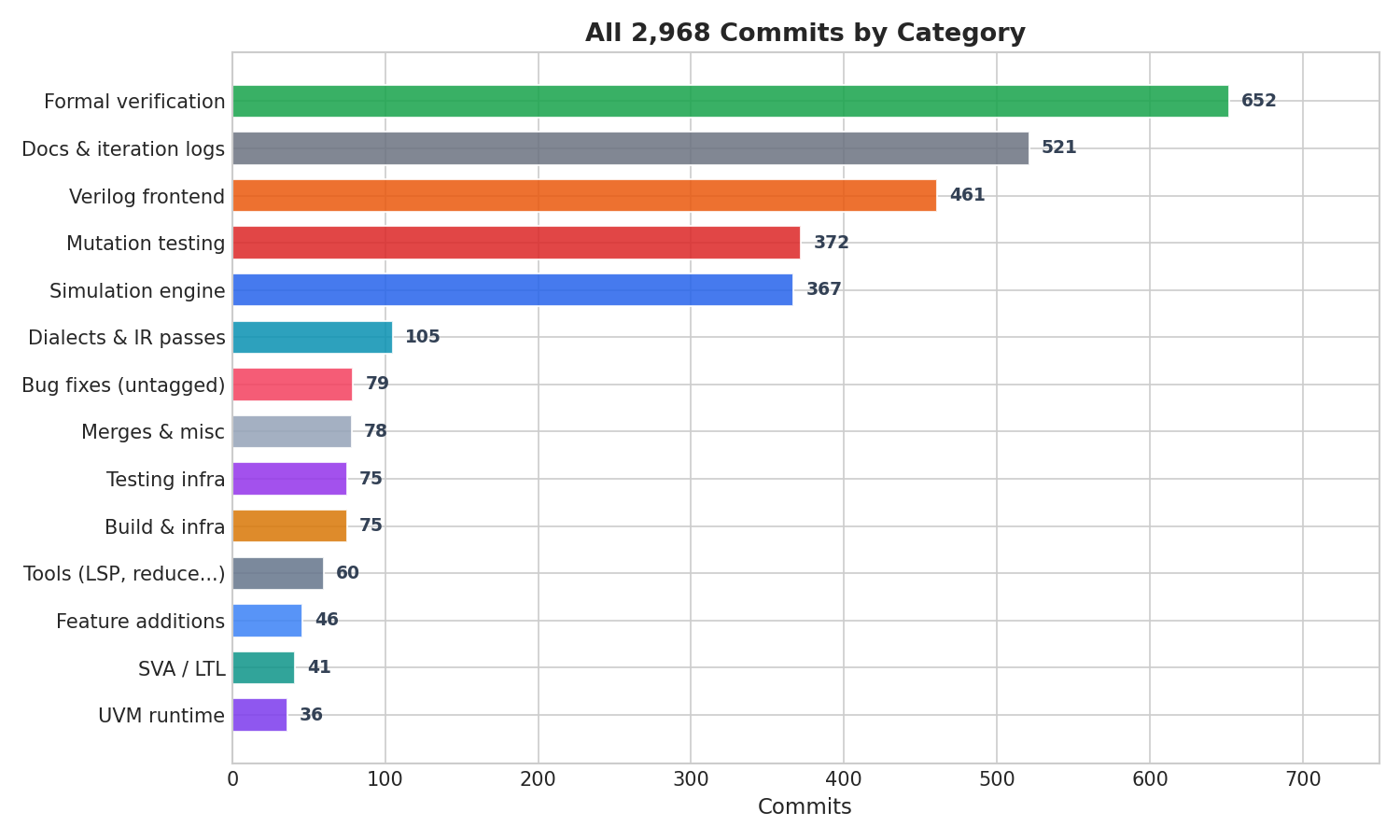
Formal verification (BMC + LEC) and mutation testing together account for over 1,000 commits — 34% of the total. The “Docs & iteration logs” category (521) reflects the project’s 1,554-iteration engineering log, which tracked every AI interaction cycle. The Verilog frontend (461 commits) covers ImportVerilog and MooreToCore, the two major lowering passes that convert parsed Verilog into simulatable IR.
How We Worked with Agents
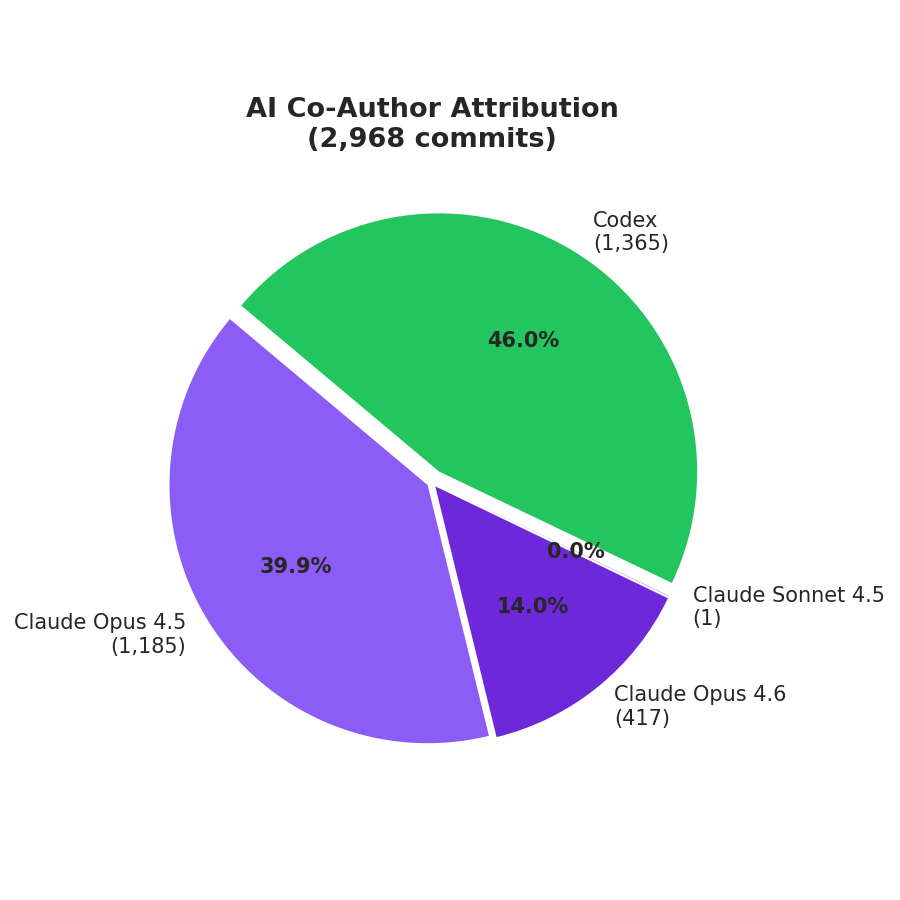
AI attribution: 40% Claude Opus 4.5, 14% Claude Opus 4.6, 46% Codex models
We used a variety of models in the AI agent software. Claude handled 54% of commits. Early work used Opus 4.5 with a custom StopHook to maintain continuity across long sessions. Opus 4.6 with team mode removed the need for that, letting the agent run autonomously through multi-step tasks.
Codex handled the remaining 46%. Version 5.2 had coordination issues with other agents, frequently reverting parallel changes. Version 5.3 resolved this, and its xhigh reasoning mode proved particularly effective on complex debugging. We build a custom auto-continue utility to maintain sessions and keep them running.
The workflow was largely asynchronous: set high-level objectives (new test suites, JIT optimization targets), then review outputs. Compiling and running Verilog at scale pushed hardware limits (64GB RAM, 256GB disk), so monitoring resource consumption was a recurring task. The agents shared an engineering log to track progress and surface blockers.
The project log records 1,554 iterations of this cycle. Many features took 3–5 iterations from first attempt to passing tests. Some — particularly UVM sequencer integration and VPI callback handling — took 20+.
Real World Testing
The real test is whether our new simulator was able to run real-world test benches designed for commercial tools. We used a variety of codebases from github for this:
AVIP Protocol Suites
Mirafra’s open-source AVIPs (Advanced Verification IP) are a set of UVM testbenches for standard bus and communication protocols, including APB, AHB, AXI4, SPI, JTAG, I2S, and I3C. Each AVIP contains a complete UVM environment with drivers, monitors, scoreboards, coverage collectors, and constrained-random sequences.
No open-source simulator can even compile a single one of these test benches, but our simulator ran each to completion. This included collecting coverage, which we verified matched the expected number for the test benches.
Besides correctness, a big issue with running larger test benches like this is get speed. A not insignificant amount of work went into adding Just In Time compilation (JIT) to the interpreter and replacing algorithms in CIRCT with ones that scaled. See the bottom of the post for more details on this.
Comprehensive Verilog Design Problems
We also ran against NVIDIA’s CVDP benchmark (Comprehensive Verilog Design Problems) — a dataset of 783 hardware design tasks created by experienced hardware engineers. Many of the testbenches use the Python library cocotb, so we had to add support for this to CIRCT as well.
We tested that our simulator could run all test benches without compilation or runtime errors.
OpenTitan and Ibex
We also added formal verification tools to CIRCT. Formal verification proves designs are correct for all inputs, rather than just a random set of tests. Bounded model checking (BMC) exhaustively checks assertions across every possible state a design can reach, and Logic equivalence checking (LEC) proves that two implementations compute the same outputs for all inputs.
We verify modules from Google’s OpenTitan project (an open-source silicon root of trust) and lowRISC’s Ibex RISC-V core. For example, circt-bmc can prove that OpenTitan’s prim_count (a counter primitive used throughout the SoC) has no assertion violations up to 20 cycles, and circt-lec can verify that Ibex’s ALU matches a reference implementation.
The dominant open-source formal tool today is SymbiYosys (SBY and EQY for BMC and LEC). It uses Z3 under the hood, but CIRCT’s approach operates on MLIR, the same intermediate representation used for simulation. This means formal and simulation share the same frontend, the same lowering passes, and the same bug fixes.
To verify our tools, we ran the equivalence test CLKMGR_TRANS_AES and FLASH_TEST_MODE_O (see opentitan/hw/top_earlgrey/formal/conn_csvs at 01cdeb9d64868d…). The first test checks AES clock-transition connectivity rule from OpenTitan’s top-level connectivity spec and proves the compared cones are equivalent. The second test checks the flash test-mode analog signal path rule in the OpenTitan top-level connectivity set and proves equivalence. EQY was not able to parse either test, due to it’s limited System Verilog Support
Performance
Let's be honest about performance. In interpret mode, circt-sim is far too slow for real-world use. Even with the JIT improvements we made, the simulator is still 100-1000x slower than the competition.
.png)
CIRCT already has a fast simulation backend: arcilator. Similar to verilator, it is assumes everything important happens at rising or falling clock edges. This is a practical assumption for many designs, and allows many compilation optimizations.
Our goal was a full 4-state event-driven simulator with an event-driven scheduler, concurrent processes, and other features critical for verification with UVM. To achieve competitive speeds, we need to build a compilation pipeline that supports the full spec.
There are three viable approaches:
- Coroutine-based — compile each process to an LLVM coroutine.
llhd.waitbecomes a coroutine suspend; the scheduler resumes it. LLVM handles saving/restoring state automatically. Cleanest abstraction, but LLVM’s coroutine machinery was designed for C++20co_await, not hardware processes, and may fight the semantics. - State-machine transformation — rewrite each process as a state machine at the IR level. Every wait point becomes a state boundary; the compiled function takes a state pointer, runs until the next wait, and returns. No coroutine dependency, but the IR transformation is complex — SSA values live across wait points must be explicitly spilled to a state struct.
- Block-level JIT — don’t compile whole processes. Instead, identify hot basic blocks (clock toggles, BFM driver loops, scoreboard arithmetic) and compile just those to native code. The interpreter still handles control flow and suspension, but inner loops run at native speed. The most incremental approach — it builds on the existing infrastructure and targets the code that dominates execution time.
The fork currently includes a --mode=compile flag that combines specialized thunks (for common patterns like clock toggles and wait loops) with a block-level JIT that compiles hot basic blocks to native code via LLVM ORC. Today this produces a 2.1x speedup on I2S and 18% on simpler benchmarks, with most processes still falling back to the interpreter for unsupported patterns. The real gains will come from expanding JIT coverage to eliminate interpreter dispatch from hot paths entirely.
The Future of Software and EDA
The AI revolution is uprooting decades of assumptions about what is complex and what is simple. The EDA industry has operated for decades on a simple assumption: verification tools are too complex for anything but large, well-funded teams to build. Commercial simulators represent millions of person-years of engineering effort.
That assumption may no longer hold.
We note that compilers and simulators may be a particularly good fit for AI, as they represent a well-scoped problem with rich testing opportunities. Also, this fork is not a replacement for commercial simulators. It hasn’t been hardened by decades of production use. But it demonstrates that a single engineer with AI assistance can build a functional verification stack in weeks, not years.
At Normal Computing we build agent software for the entire custom silicon flow. Verification in particular represents a more challenging problem to AI, because there is no easy way to “test when you have done enough testing”.
The cost of building verification tools is dropping by an order of magnitude. Whether that leads to better open-source tools, more specialized commercial tools, or something else entirely. But the gap between “possible” and “practical” just got a lot smaller.
The fork is at github.com/thomasnormal/circt. Join us on Discord if you want to dig in.